2020年5月底OpenAI发布了有史以来最强的NLP预训练模型GPT-3,最大的GPT-3模型参数达到了1750亿个参数。论文《Language Models are Few-Shot Learners》长达74页已发布在arXiv。
有网友估算最大的GPT-3模型大小大约有700G,这个大小即使OpenAI公开模型,我们一般的电脑也无法使用。一般需要使用分布式集群才能把这个模型跑起来。虽然OpenAI没有公布论文的花费,不过有网友估计这篇论文大约花费了上千万美元用于模型训练。
如此惊人的模型在模型的设计上和训练上有什么特别之处吗?答案是没有。作者表示GPT-3的模型架构跟GPT-2是一样的,只是使用了更多的模型参数。模型训练也跟GPT-2是一样的,使用预测下一个词的方式来训练语言模型,只不过GPT-3训练时使用了更多的数据。
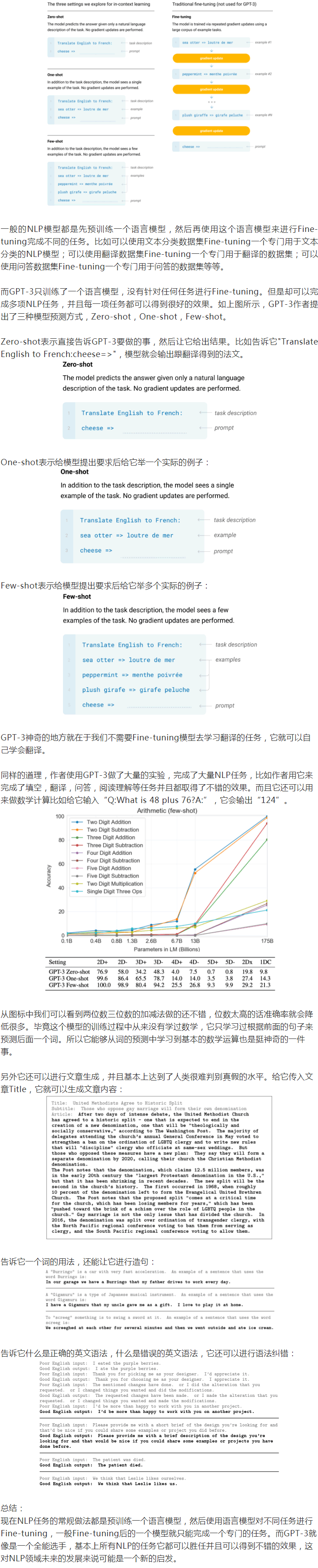
既然这样,那这只怪兽特别之处是什么?GPT-3论文的核心在于下图:
达摩院金榕教授介绍了语音、自然语言处理、计算机视觉三大核心AI技术的关键进展,并就AI技术在在实际应用中的关键挑战,以及达摩院应对挑战的创新实践进行了解读
新一代移动端深度学习推理框架TNN,通过底层技术优化实现在多个不同平台的轻量部署落地,性能优异、简单易用。腾讯方面称,基于TNN,开发者能够轻松将深度学习算法移植到手机端高效的执行,开发出人工智能 App,真正将 AI 带到指尖
新加坡国立大学NExT中心的王翔博士分析了知识图谱在个性化推荐领域的应用背景,并详细介绍了课题组在个性化推荐中的相关研究技术和进展,包括基于路径、基于表征学习、基于图神经网络等知识图谱在推荐系统中的融合技术
根据各种指法的具体特点,对时频网格图、时域网格图、频域网格图划分出若干个不同的计算区域,并以每个计算区域的均值与标准差作为指法自动识别的特征使用,用于基于机器学习方法的指法自动识别
Tube Feature Aggregation Network(TFAN)新方法,即利用时序信息来辅助当前帧的遮挡行人检测,目前该方法已在 Caltech 和 NightOwls 两个数据集取得了业界领先的准确率
姚霆指出,当前的多模态技术还是属于狭隘的单任务学习,整个训练和测试的过程都是在封闭和静态的环境下进行,这就和真实世界中开放动态的应用场景存在一定的差异性
优酷智能档突破“传统自适应码率算法”的局限,解决视频观看体验中高清和流畅的矛盾
通过使用仿真和量化指标,使基准测试能够通用于许多操作领域,但又足够具体,能够提供系统的有关信息
基于内容图谱结构化特征与索引更新平台,在结构化方面打破传统的数仓建模方式,以知识化、业务化、服务化为视角进行数据平台化建设,来沉淀内容、行为、关系图谱,目前在优酷搜索、票票、大麦等场景开始进行应用
NVIDIA解决方案架构师王闪闪讲解了BERT模型原理及其成就,NVIDIA开发的Megatron-BERT
自然语言处理技术的应用和研究领域发生了许多有意义的标志性事件,技术进展方面主要体现在预训练语言模型、跨语言 NLP/无监督机器翻译、知识图谱发展 + 对话技术融合、智能人机交互、平台厂商整合AI产品线
下一个十年,智能人机交互、多模态融合、结合领域需求的 NLP 解决方案建设、知识图谱结合落地场景等将会有突破性变化